[HADOOP] 하둡 에코시스템 기능 설명
업데이트:
※ 출처 : https://butter-shower.tistory.com/73
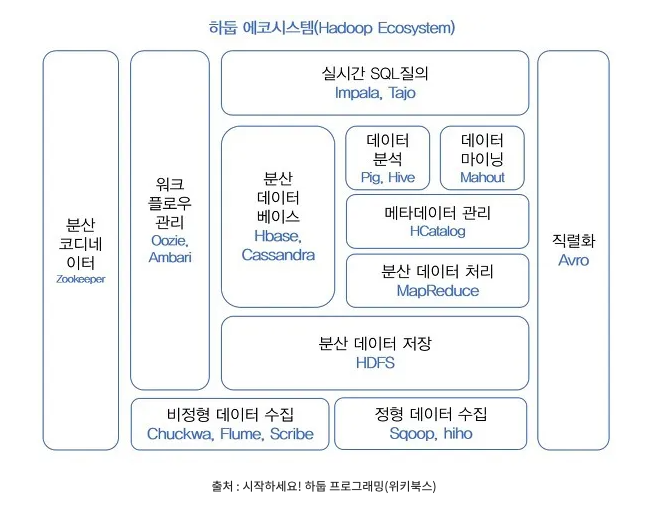
- 하둡의 코어 프로젝트 : HDFS(분산 데이터 저장), MapReduce(분산 처리)
- 하둡의 서브 프로젝트 : 나머지 프로젝트들 -> 워크플로우 관리, 데이터 마이닝, 분석, 수집, 직렬화 등등
▢ Zookeeper
분산 환경에서 서버들간에 상호 조정이 필요한 다양한 서비스를 제공하는 시스템.
- 하나의 서버에만 서비스가 집중되지 않도록 서비스를 알맞게 분산하여 동시에 처리하게 해줌
- 하나의 서버에서 처리한 결과를 다른 서버들과도 동기화 -> 데이터 안정성 보장
- 운영(active) 서버에서 문제가 발생해 서비스를 제공할 수 없는 경우, 다른 대기중인 서버를 운영 서버로 바꿔 서비스가 중지없이 제공되게 해줌
- 분산 환경을 구성하는 서버들의 환경설정을 통합적으로 관리
공식 사이트 : http://zookeeper.apache.org/
▢ Ooozie
하둡의 작업을 관리하는 워크플로우 및 코디네이터 시스템
자바 서블릿 컨테이너에서 실행되는 자바 웹어플리케이션 서버로, MapReduce 작업이나 Pig 작업 같은 특화된 액션들로 구성된 워크플로우를 제어함.
공식 사이트 : http://incubator.apache.org/oozie
▢ HBase
HDFS의 칼럼 기반 데이터베이스
구글의 BigTable 논문을 기반으로 개발된 것으로, 실시간 랜덤 조회 및 업데이트가 가능하며, 각각의 프로세스들은 개인의 데이터를 비동기적으로 업데이트 할 수 있다. 단, MapReduce는 일괄처리 방식으로 수행된다.
공식 사이트 : http://hbase.apache.org
▢ Pig
복잡한 MapReduce 프로그래밍을 대체할 Pig Latin이라는 자체 언어를 제공.
MapReduce API를 매우 단순화시키고 SQL과 유사한 형태로 설계되었다.
공식 사이트 : http://pig.apache.org
▢ Hive
하둡 기반의 데이터웨어하우징용 솔루션
페이스북에서 만든 오픈소스로, SQL과 매우 유사한 HiveQL이라는 쿼리를 제공한다. 그래서 자바를 잘 모르는 데이터 분석가들도 쉽게 하둡 데이터를 분석할 수 있게 도와준다.
HiveQL은 내부적으로 MapReduce 잡으로 변환되어 실행된다.
공식 사이트 : http://hive.apache.org
▢ Mahout
하둡 기반 데이터 마이닝 알고리즘을 구현한 오픈소스.
현재 분류(classification), 클러스터링(clustering), 추천 및 협업 필터링(Recommenders/Collavorative filtering), 패턴 마이닝(Pattern Mining), 회귀 분석(Regression), 차원 리덕션(Dimension Reduction), 진화 알고리즘(Evolutionary Algorithms) 등 주요한 알고리즘을 지원하고 있다.
Mahout을 그대로 사용할 수도 있지만, 자신의 비즈니스 환경에 맞게 최적화 해 사용하는 경우가 대부분.
공식 사이트 : http://mahout.apache.org
▢ HCatalog
하둡으로 생성한 데이터를 위한 테이블 및 스토리지 관리 서비스
HCatalog의 가장 큰 장점은 하둡 에코 시스템들간의 상호 운용성 향상이다. 예를 들어 Hive에서 생성한 테이블이나 데이터 모델을 Pig나 MapReduce에서 손쉽게 이용할 수가 있다.
공식 사이트: http://incubator.apache.org/hcatalog)
▢ Avro
RPC(Remote Procedure Call)과 데이터 직렬화를 지원하는 프레임워크
JSON을 이용해 데이터 형식과 프로토콜을 정의하며, 작고 빠른 바이너리 포맷으로 데이터를 직렬화한다.
공식 사이트: http://avro.apache.org/)
▢ Chukwa
분산 환경에서 생성되는 데이터를 HDFS에 안정적으로 저장시키는 플랫폼
분산된 각 서버에서 에이전트(agent)를 실행하고, 콜랙터(collector)가 에이전트로부터 데이터를 받아 HDFS에 저장한다. 콜렉터는 100개의 에이전트당 하나씩 구동되며, 데이터 중복 제거 등의 작업은 MapReduce로 처리합니다.
공식 사이트: http://incubator.apache.org/chukwa)
▢ Flume
Chukwa 처럼 분산된 서버에 에이전트가 설치되고, 에이전트로부터 데이터를 전달받는 콜랙터로 구성
차이점은 전체 데이터의 흐름을 관리하는 마스터 서버가 있어서, 데이터를 어디서 수집하고, 어떤 방식으로 전송하고, 어디에 저장할 지를 동적으로 변경할 수 있다.
공식 사이트: http://incubator.apache.org/projects/flume.html)
▢ Scribe
페이스북에서 개발한 데이터 수집 플랫폼이며, Chukwa와는 다르게 데이터를 중앙 집중 서버로 전송하는 방식이다.
최종 데이터는 HDFS외에 다양한 저장소를 활용할 수 있으며, 설치와 구성이 쉽게 다양한 프로그램 언어를 지원함.
HDFS에 저장하기 위해서는 JNI(Java Native Interface)를 이용해야 한다.
공식 사이트: https://github.com/facebook/scribe)
▢ Sqoop
대용량 데이터 전송 솔루션.
Sqoop은 HDFS, RDBMS, DW, NoSQL등 다양한 저장소에 대용량 데이터를 신속하게 전송할 수 있는 방법을 제공한다.
Oracle, MS-SQL, DB2 등과 같은 상용 RDBMS와 MySQL, PostgresSQL과 같은 오픈소스 RDBMS등을 지원합니다.
공식 사이트: http://sqoop.apache.org/)
▢ Hiho
Sqoop과 같은 대용량 데이터 전송 솔루션이며, 현재 github에서 공개되어 있습니다. 하둡에서 데이터를 가져오기 위한 SQL을 지정할 수 있으며, JDBC 인터페이스를 지원합니다.
공식 사이트: https://github.com/sonalgoyal/hiho)
▢ Impala
클라우드데라에서 개발한 하둡 기반의 실시간 SQL 질의 시스템
. 맵리듀스를 사용하지 않고, 자체 개발한 엔진을 사용해 빠른 성능을 보여줍니다.
임팔라(Impala)는 데이터 조회를 위한 인터페이스로, HiveQL을 사용합니다. 수초 내에 SQL 질의 결과를 확인할 수 있으며, HBase와도 연동이 가능합니다.
공식 사이트 : https://github.com/cloudera/impala)
▢ Tajo
고려대학교 정보통신대학 컴퓨터학과 DB연구실 박사 과정학생들이 주도해서 개발한 하둡 기반의 DW 시스템.
데이터 저장소는 HDFS를 사용하되, 표준DB언어인 SQL을 통해 실시간으로 데이터를 조회할 수 있습니다. Hive보다 2 ~ 3배 빠르며, 클라우드데라의 임팔라(Impala)와는 비슷한 속도를 보여줍니다. 임팔라가 클라우드데라의 하둡을 써야 하는 제약에 비해, 특정 업체 솔루션에 종속되지 않는 장점이 있습니다.
공식 사이트 : http://tajo.incubator.apache.org/)
공유하기
Twitter Facebook LinkedIn◻ Sponsored by